

High-performance network solution for artificial intelligence(AI)
The rapid growth of AI-Generated Content (AIGC) like GPT-4 and Ernie Bot has sparked interest. With expanding training model parameters and increased GPU support, AI networks face communication challenges. Ruijie Networks introduces the “Smart Speed” DDC solution to enhance computing power, GPU utilization, and tackle HPC networking obstacles in the Artificial Intelligence Network domain.
Table of Contents
The relationship between AI computing power, GPU utilization and network
To calculate the time, it takes to train using 10,000 NVidia V100 GPUs on the Microsoft Azure AI supercomputing infrastructure, you need the total computing power consumption, which is 3640 PF-days (quadrillion floating-point operations per second computed over 3640 days).
First, let’s convert the computing power consumption from PF-days to FLOPs (floating-point operations). Since there are 24 hours in a day, we have:
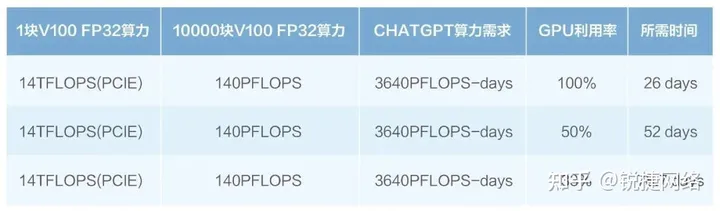
Note: ChatGPT’s computing power requirements are obtained online and are for reference only. OpenAI assumes a utilization rate of 33% in their article “AI and Compute”. A team of researchers from NVIDIA, Stanford, and Microsoft achieved utilization rates ranging from 44% to 52% for training large language models on distributed systems.
Network Efficiency vs. GPU Utilization
Network efficiency plays a crucial role in AI training, especially in AI clusters with multiple computing and storage nodes. Effective communication and data exchange between these nodes are vital for optimizing GPU utilization in artificial intelligence networks.
Low network efficiency can result in several issues that hinder GPU utilization:
Increased data transfer time: Inefficient networks lead to longer data transfer durations. This delays GPU calculations, reducing GPU utilization.
Network bandwidth bottleneck: Insufficient network bandwidth restricts the amount of data available for GPU calculations, resulting in decreased GPU utilization in AI clusters.
Unbalanced task scheduling: Inefficient networks may assign tasks to computing nodes that differ from the GPUs, causing GPUs to idle while waiting for significant data transfers. This decreases GPU utilization.
To enhance GPU utilization, it is crucial to optimize network efficiency through the following approaches:
Adoption of faster network technology: Upgrading to faster network technologies improves data transfer speeds and reduces latency, enhancing overall network efficiency in AI training.
Optimization of network topology: Careful design and configuration of the network topology minimizes bottlenecks and optimizes data flow between nodes, boosting GPU utilization.
Bandwidth configuration: Proper allocation and configuration of network bandwidth among computing and storage nodes ensure that GPUs have sufficient data for processing, maximizing GPU utilization.
Furthermore, in the training model, the parallelism of distributed training, such as data parallelism, tensor parallelism, and pipeline parallelism, determines the communication model between the data processed by GPUs. Addressing various factors that impact communication efficiency between models can further optimize GPU utilization in artificial intelligence networks.
What may trigger speed reduction
The current prevailing networking solution for high-performance networks involves constructing a network that supports Remote Direct Memory Access (RDMA) based on RDMA over Converged Ethernet (RoCE) v2. Two important matching technologies in this context are Priority Flow Control (PFC) and Explicit Congestion Notification (ECN). Both of these technologies aim to prevent congestion in the network link.
PFC operates by gradually propagating congestion from the ingress of a switch back to the source server, suspending data transmission to alleviate network congestion and prevent packet loss. However, in multi-level networks, there is a risk of PFC Deadlock, which can halt RDMA (Remote Direct Memory Access) traffic forwarding.
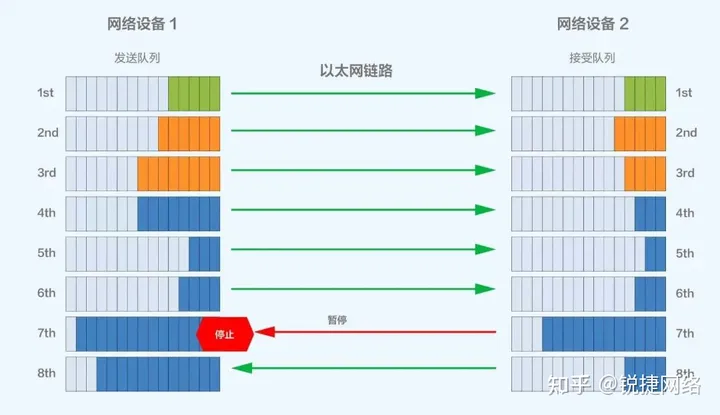
ECN directly generates a RoCEv2 (RDMA over Converged Ethernet) Congestion Notification Packet (CNP) at the egress switch to notify the source server to slow down its transmission. This approach aims to promptly address congestion without introducing additional pauses or prioritization.
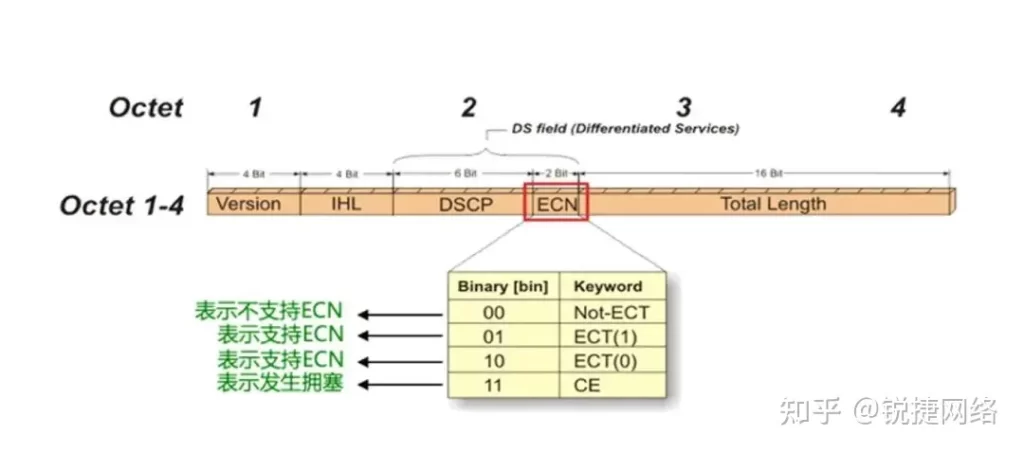
There is no problem with these two technologies in themselves, and they are all technologies born to solve congestion. However, after adopting this technology, it may be frequently triggered by possible congestion in the network, which will eventually cause the source to suspend or slow down the transmission. The communication bandwidth will be reduced, which will have a relatively large impact on the utilization of the GPU, thereby reducing the computing power of the entire high-performance network.
ECMP (Equal-Cost Multipath) imbalance lead to network ‘s congestion
In AI training computing, there are two main models, All-Reduce and All-to-All, and both models require frequent communication from one GPU to multiple other GPUs.
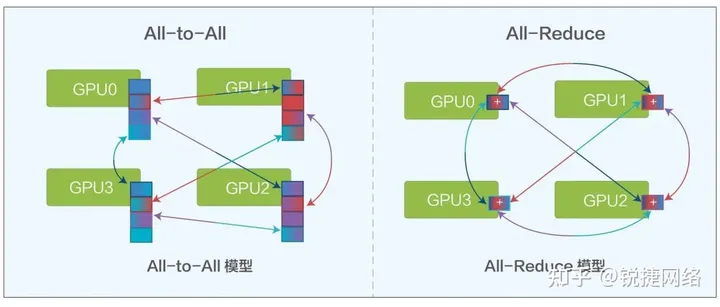
In traditional networking, ToR and Leaf devices use the routing + ECMP networking mode. ECMP will perform hash load routing based on the flow. In an extreme case, a certain ECMP link is full due to an elephant flow, and the rest Multiple ECMP links are relatively idle, resulting in uneven load.
To address these challenges, the research community has put forward various solutions such as phost, Homa, NDP, 1RMA, and Aeolus. These solutions tackle incast issues, load balancing, and low-latency request/response traffic to different extents. However, implementing these solutions poses new challenges. Often, they require end-to-end problem-solving, necessitating significant changes to the host, network card, and network infrastructure.
Challenges of AI Clusters
Overseas Internet companies are exploring the use of modular switches with DNX chips and VOQ (Virtual Output Queueing) technology to address low bandwidth utilization caused by unbalanced loads. However, they encounter the following challenges:
Limited expansion capability: Modular switches have average expansion capabilities, and the size of the chassis sets a maximum limit on the number of ports. To create a larger-scale cluster, multiple chassis need to be horizontally expanded. This leads to the generation of multi-level PFC (Priority Flow Control) and ECMP (Equal-Cost Multipath) links, making the chassis suitable only for small-scale deployments.
High power consumption: The equipment in the chassis, including line card chips, fabric chips, and fans, consumes a significant amount of power. The power consumption of a single device can exceed 20,000 watts, and in some cases, even exceed 30,000 watts. This high power consumption requirement necessitates robust power infrastructure for the cabinet.
A new solution form Artificial Intelligence Network
DDC (Distributed Decoupling Chassis) is a solution that offers advantages such as elastic expansion, rapid function iteration, easier deployment, and low power consumption for individual machines. The architecture utilizes similar chips and key technologies as traditional chassis switches but with a simplified design. DDC enables the scalability of networks based on the size of the AI cluster.

In a single POD network, DDC employs 96 NCPs (Network Card Ports) as access points, connecting the AI computing cluster’s network cards. It supports 36 NCP downlink 200G interfaces and 40 uplink 200G interfaces connected to a maximum of 40 NCFs (Network Card Fabrics). NCFs provide a total of 96 200G interfaces, resulting in an overspeed ratio of 1.1:1. This configuration allows the POD to accommodate 3,456 200G network interfaces, supporting up to 432 AI computing servers equipped with 8 GPUs each.
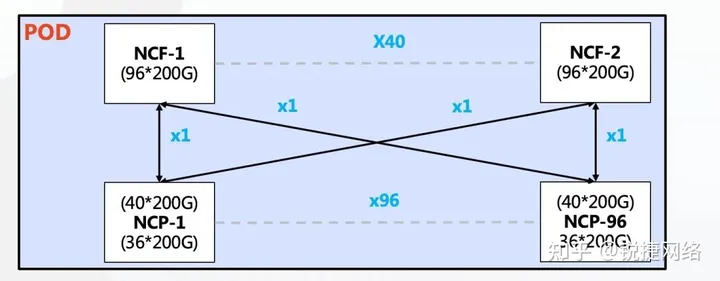
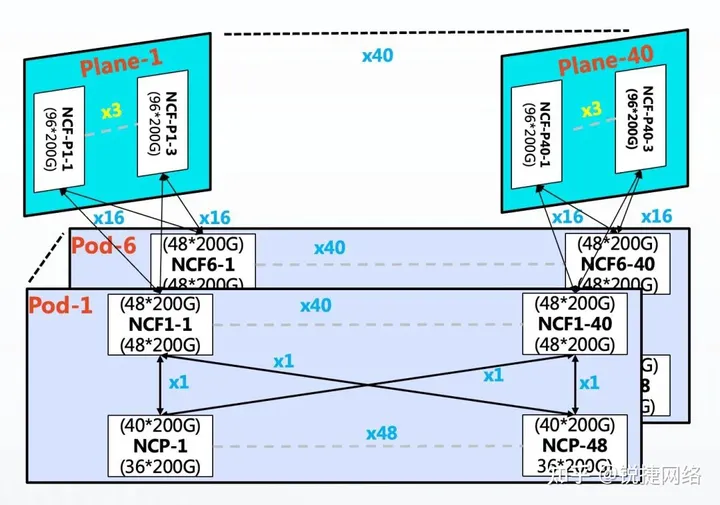
In multi-level POD networking, scalability is achieved by horizontally adding PODs. Each POD uses 48 NCPs for access and supports 36 downlink 200G interfaces. A single POD can accommodate 1,728 200G interfaces, and the overall network can support over 10,368 200G network ports. The NCFs in the POD use 48 200G interfaces for downlink, with 16 groups of uplinks connecting to the second-level NCFs. The second-level NCFs are organized into 40 planes, with each plane designed with 3 units corresponding to 40 NCFs in the POD. The convergence ratio between the POD and the secondary NCF is 1:1, while an overspeed ratio of 1.1:1 is maintained within the POD.
In terms of network performance, DDC eliminates multi-level PFC (Priority Flow Control) suppression and deadlock by considering all NCPs and NCFs as one device. This enables the deployment of RDMA (Remote Direct Memory Access) without encountering multi-level PFC issues. Furthermore, DDC supports the deployment of ECN (Explicit Congestion Notification) at the interface, allowing for the reduction of speed upon burst traffic if the internal Credit and cache mechanism cannot handle it.
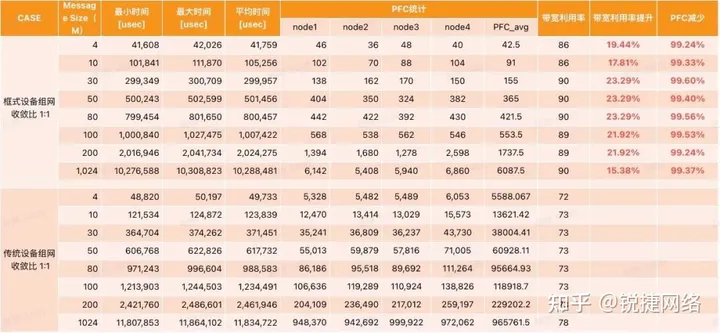
Comparisons and simulation tests using the OpenMPI test suite have shown that in All-to-All scenarios, the bandwidth utilization rate of DDC devices is approximately 20% higher than that of traditional networking devices. This corresponds to an increase of around 8% in GPU utilization.
Ruijie Equipment Introduction
Ruijie Networks, as an industry leader, is dedicated to delivering high-quality and reliable network equipment and solutions to fulfill the growing demands of intelligent computing centers. Alongside their “Smart Speed” DDC solution, Ruijie Networks is actively engaged in the exploration and development of end-network optimization solutions for traditional networking. Through leveraging server smart network cards and optimizing network device protocols, they aim to enhance the overall bandwidth utilization of the network, enabling customers to embrace the era of AIGC (AI-Generated Content) intelligent computing more efficiently.
Ruijie Networks has introduced two tangible products, namely the 200G NCP switches and the 200G NCF switches, in response to a comprehensive understanding of customer requirements. These products are designed to meet the growing demands of high-speed networking and provide effective solutions for customers.
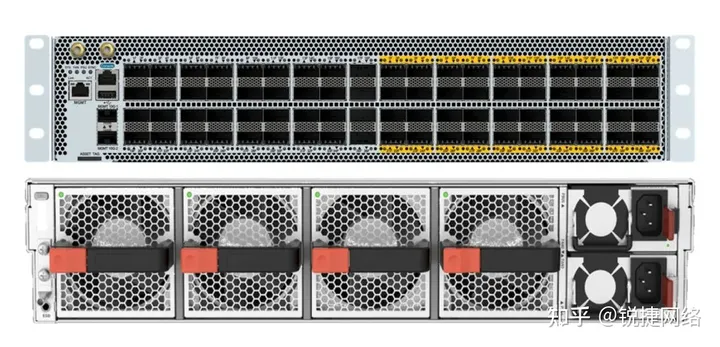
The Ruijie RG-S6930-36DC40F1 is 2U in height and provides 36 200G panel ports, 40 200G Fabric inline ports, 4 fans and 2 power supplies.

The Ruijie RG-X56-96F1 switch is 4U high and provides 96 200G Fabric inline ports, 8 fans and 4 power supplies.
Conclusions
Upgrading your network infrastructure is crucial inside artificial intelligence datacenters in the face of rapid AI training advancements and the growing scale of AI clusters. By improving network efficiency, you can overcome challenges such as data transfer delays, bandwidth limitations, and unbalanced task scheduling, ultimately enhancing the computing power of your high-performance network.
1 Comment